DIE ERGEBNISSE DER GENETISCHEN ZUSAMMENSETZUNG IM GLOBALEN KONTEXT – EINE ZUSAMMENARBEIT MIT DER UNIVERSITÄT „TEXAS AT TYLER“.
Eines der Hauptmerkmale von ADNTRO ist die Beschreibung der Zusammensetzung der Abstammung jedes Individuums (zusammen mit Vitaminstoffwechsel, Sport, Verhalten, Veranlagung für Krankheiten ...) usw., aber alle von uns durchgeführten Analysen haben Inspirationsquelle die besten Studien zu diesem Thema.
Diese alternative Methode der Ahnenanalyse basiert auf einer Veröffentlichung in Nature (einer der renommiertesten wissenschaftlichen Zeitschriften der Welt) und auf der Datenbank 1000 Genomes; Obwohl diese Methodik es uns nicht erlaubt, die detaillierte Aufschlüsselung nach Ländern anzubieten, die wir in unserem ADNTRO-Ahnenrechner anbieten, ist es eine sehr robuste Methode, mit der Sie lernen können, wie die Vorfahren einer Person analysiert werden .
Erreichen die Beschreibung der Abstammungszusammensetzung, verwenden wir Computational Pipelines (Workflows für „Big Data“ – große Datensätze – die die Rechenleistung von Google Cloud nutzen) um Vergleichen Sie Ihre DNA mit der vieler anderer Personen auf der ganzen Welt, in diesem Fall unter Verwendung der 1000 Genome-Datenbank als Ausgangspunkt, die 2.504 genetische Profile von anonymen Individuen aus 26 verschiedenen Weltpopulationen umfasst (weitere Details finden Sie im Abschnitt „Zusätzliche Informationen“ weiter unten).
Basierend auf Ihrer genetischen Ähnlichkeit, unsere Computeralgorithmen machen Vorhersagen über Welcher Teil deiner Vorfahren stammt aus verschiedenen Teilen der Welt und aus welchen.
Es ist wichtig, die Ergebnisse in einen globalen Kontext zu stellen . Einige Menschen auf der ganzen Welt haben Vorfahren, die in der Region, aus der sie stammen, einzigartig sind, aber viele andere haben gemischte Vorfahren , die möglicherweise Muster der menschlichen Migration in der fernen Vergangenheit oder in jüngster Zeit widerspiegeln (z anderer Kontinent).
ADNTRO hat mit dem . zusammengearbeitet Dr. Joshua Banta, Professor für Biologie an der University of Texas in Tyler, der die Genetik natürlicher Populationen untersucht und veröffentlicht und Big Data nutzt, um Ihnen ein visuelles Tool, das Ihre genetischen Ergebnisse in einen globalen Kontext stellt.
Wenn wir ein wenig mehr auf die Methodik eingehen, möchten wir Ihnen sagen, dass wir einen nicht-negativen Matrixfaktorierungsalgorithmus (sNMF) verwenden, der durch die Funktion implementiert wird 'snmf' aus dem LEA-Paket gehört zur Programmiersprache R. Dieser Algorithmus schätzt die Beiträge zum Genom hypothetischer Ahnengruppen jedes Individuums in der Analyse, basierend auf den genetischen Ähnlichkeiten / Unterschieden der DNA-Sequenzen untereinander.
Um die optimale Anzahl von Vorfahrengruppen (K) zu finden, wurden verschiedene Anzahlen von hypothetischen Vorfahren simuliert und die verschiedenen Simulationen verglichen, um zu bestimmen, welche am besten zu den von uns behandelten Daten passt und daher welche Anzahl von K-Gruppen verwendet werden sollte. für dieses neue Werkzeug. Wir testeten verschiedene Anzahlen von K-Gruppen zwischen 5 und 12 unter Verwendung des Entropiekriteriums der sNMF-Funktion, die die Qualität der Anpassung des statistischen Modells an die Daten mithilfe einer Kreuzvalidierungstechnik bewertet (siehe zusätzliche Informationen (1)).
Das Modell mit einer bestimmten Anzahl von K-Gruppen wird bevorzugt, wenn das Entropiekriterium minimiert wird (siehe Zusatzinformationen (2)).
Basierend auf diesen Kriterien stellen wir fest, dass die optimale Anzahl von K-Gruppen 5 beträgt (Abbildung 1).
Weitere Informationen zu den Methoden finden Sie in den zusätzlichen Informationen am Ende des Artikels).
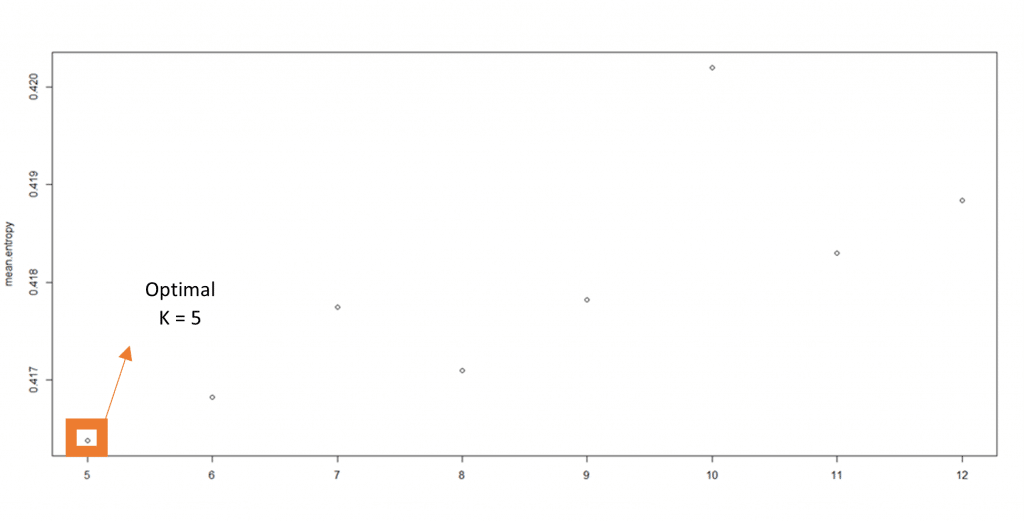
Abbildung 1. Die Anzahl der Ahnengruppen ist für einen Wert von fünf optimal. Die Entropie wird minimiert, wenn der Wert von K fünf ist, wobei fünf die Zahl ist, die am besten zu unseren Daten passt.
IHRE ZUSAMMENSETZUNG DER ANSÄTZE AUF GEOGRAFISCHER EBENE
Diese fünf Vorfahrengruppen können visuell beschrieben werden als Afrikanische Vorfahren (in rot), Amerindian (in grün), Westeurasien (in hellblau), Ostasien (in gelb) und Südasien (in orange).
Um den Beitrag dieser Vorfahrengruppen in Ihrer DNA zu ermitteln, führen wir die Analyse mit Daten von 1000 Genomes zusammen mit Ihren Daten durch, um Ergebnisse zu generieren, die Ihre Abstammung in einem globalen Kontext berücksichtigen.
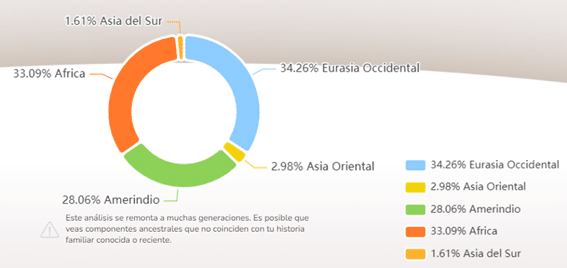
Abbildung 2. Diagramm mit einer Aufschlüsselung der fünf Hauptkomponenten und dem prozentualen Anteil dieser Komponenten.
Anhand dieses Diagramms können Sie das Muster der Vorfahrengruppen, d. h. den Beitrag der verschiedenen Vorfahren zu Ihrer DNA und zum Rest der 1000G-Populationen, deutlicher erkennen. Sie werden auch sehen können, wie ähnlich Sie den verschiedenen 1000G-Populationen sind (Abbildung 3).
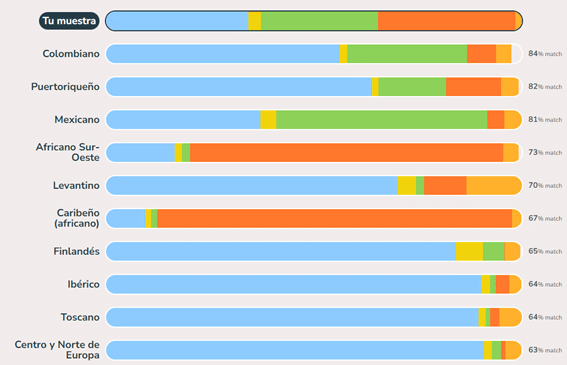
Abbildung 3: Diagramm, das die fünf Mehrheitskomponenten aufschlüsselt und die genetische Ähnlichkeit mit den verschiedenen 1000G-Populationen angibt.
Jedes mehrfarbige Segment steht für eine Hauptkomponente. Das Individuum in diesem Beispiel hat gemischte Farben aufgrund geringer Mengen gemischter Abstammung. Interessanterweise weisen die genetischen Profile der Völker Amerikas die größte Variabilität auf.
Es gibt viele Personen, deren Vorfahren zu einem großen Teil aus Westeurasien stammen (hellblau), aber auch viele, die afrikanische Vorfahren haben (rot). Dies spiegelt die komplexe Geschichte afrikanischer Völker mit dem Sklavenhandel und mit den Völkern Amerikas wider, wo sich indigene Völker mit europäischen Siedlern vermischten.
Ahnenmuster
Wenn Sie bereits Teil der ADNTRO-Community sind, wissen Sie, dass wir gerne weiter gehen, kreativ sind und unseren Nutzern innovative Ergebnisse bieten. Aus diesem Grund haben wir a vergleichender Betrachter von Ahnenmustern basierend auf Korrelationen. Daten von verwenden 1000 Genome und deine haben wir analysiert wie ähnlich und wie unterschiedlich ist Ihre DNA von der "typischen" DNA der 26 verschiedenen Populationen von 1000 Genome.
Dies ist eine neue Art, Ihre Vorfahren zu betrachten. Die Bereiche des Diagramms (Abbildung 4), die Sie am höchsten sehen, sind die Populationen, mit denen Sie eine große Anzahl spezifischer Marker teilen, die in dieser Population vorhanden sind. Im Gegenteil, die untersten Bereiche des Diagramms stellen die Populationen dar, mit denen Sie die geringste Ähnlichkeit aufweisen.
Bei ADNTRO bieten wir gerne neue Perspektiven und Innovationen, wobei wir immer daran denken, wie wichtig es ist, Ihre DNA als Ganzes zu verstehen. das ist was ermöglicht es Ihnen, Ihr Ahnenmuster zu erhalten und es mit verschiedenen Ahnenmustern weltweit zu vergleichen. Etwas noch nie dagewesenes in der Welt von Gentest heute direkt an den Verbraucher.
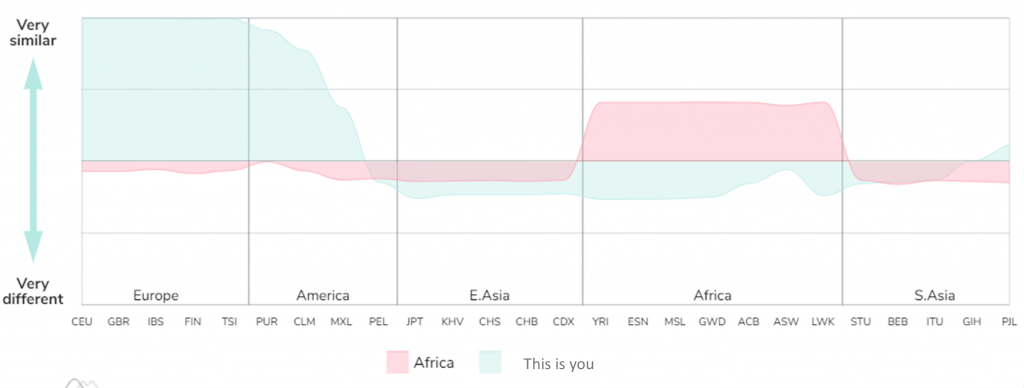
Abbildung 4. Vergleich des „typischen“ afrikanischen Musters mit Ihrem. Diese Grafik ist ein Beispiel, in dem wir eine europäische Stichprobe verwenden. Das Muster ändert sich jedoch entsprechend Ihrer genetischen Informationen. Auf dieselbe Weise können Sie die Referenzpopulationen ändern, mit denen Sie sich selbst vergleichen möchten.
Die Tatsache, dass Ihr Muster sehr ähnlichen Populationen ähnelt wie Sie, ist ganz normal. Zwei europäische Individuen haben zum Beispiel ein sehr ähnliches Muster, wenn wir es als Ganzes betrachten und nur kleine Unterschiede darstellen, die es wert sind, untersucht zu werden (die Unterschiede sind so klein, dass wir sie logarithmisch übertreiben müssten).
Es ist wichtig, dass Sie bedenken, dass die Tatsache, dass Ihr Muster eine sehr hohe Ähnlichkeit mit einer anderen Person aufweist, nicht bedeutet, dass Sie auf Familienebene verwandt sind , sondern dass Ihr Ahnenmuster sehr ähnlich ist, weil Sie gemeinsame Vorfahren haben .
Aber damit ist noch nicht Schluss! Wir werden Ihnen auch sagen, mit welchen Populationen von 1000 Genomen Sie am meisten ähneln und mit welchen Sie einen größeren Unterschied aufweisen. Wenn Sie bereits ADNTRO-Kunde sind, können Sie Ihr Muster zusammen mit einer Referenzpopulation und einem Alias hochladen, um es mit anderen Mustern in der Welt zu teilen, die nicht in der 1000G-Datenbank enthalten sind.
Gefällt Ihnen dieses Tool, sind Sie neugierig auf Ihr Abstammungsmuster in einem globalen Kontext, möchten Sie es mit anderen vergleichen können, geben Sie DNA ein 😊, kaufen Sie Ihre Abstammungs-DNA-Test oder laden Sie Ihr Raw hoch und finden Sie es heraus!
WEITERE INFORMATIONEN
(1) Sie können Seite 926 des Artikel, in der ersten Spalte, unten auf der Seite, im Abschnitt "Analyse der Bevölkerungsstruktur")
(2) Sie können Seite 927 des Artikel, schlussendlich.
Mehr Details zu den Methoden: Sowohl für die 1000 Genome Datensätze als auch für Ihre eigenen Ergebnisse filtern wir unsere Datenbank der Polymorphismen (SNPs) so, dass sie nur bei solchen bleiben, die biallelisch sind, mit einem MAF ≥ 0,05 und mit einem Abstand von mindestens 2kb.
Welche Populationen umfasst das 1000- Genome-Projekt? :
- Afrikanische Vorfahren im Südwesten der USA [ASW]
- Afrikanische Karibik in Barbados [ACB]
- Bengalisch in Bangladesch [BEB]
- Briten aus England und Schottland [GBR]
- Chinesisches Dai in Xishuangbanna, China [CDX]
- Nordeuropäer aus Utah und TSI bedeutet Toskaner aus Italien [CEU]
- Kolumbianisch in Medellin, Kolumbien [CLM]
- Esan in Nigeria [ESN]
- Finnisch in Finnland [ENDE]
- Gujarati-Indianer in Houston, Texas, USA []
- Han-Chinesen in Peking, China [CHB]
- Han-Chinesen Süd [CHS]
- Iberische Bevölkerung in Spanien [RDS]
- Indisches Telugu in Großbritannien [UND SIE]
- Japanisch in Tokio, Japan [JPT]
- Kinh in Ho-Chi-Minh-Stadt, Vietnam [KHV]
- Luhya in Webuye, Kenia [LWK]
- Mende in Sierra Leone [MSL]
- Mexikanische Vorfahren in Los Angeles CA USA [MXL]
- Peruaner in Lima Peru [PEL]
- Puertoricaner in Puerto Rico [PUR]
- Punjabi in Lahore, Pakistan [PJL]
- Sri Lanka Tamil in Großbritannien [STU]
- Toskana in Italien [TSI]
- Yoruba in Ibadan, Nigeria [YRI]
- Gambier in der Western Division - Mandinka [GWD]